En quoi a consisté cette modification ? Bonne question. Beaucoup de petites choses en fait.
Quelques points non exhaustifs :
- Changement de poids. Auparavant, Alyze attribuait un poids au
title, un poids à lameta descriptionet un autre poids aubody. Maintenant, la page dispose d'un seul et même poids de départ. Le titre et la description sont pondérés comme les autres balises. - Création de filtres. Quelques filtres viennent améliorer la précision du classement, l'un des plus importants est celui prenant en compte les "liaisons fortes". Par exemple, une expression comme "assurance-vie" sera un peu mieux classée que "assurance vie" car le tiret lie fortement ces deux termes. C'est tout simplement dû au fait que des mots séparés par des tirets ont plus de chances d'être un seul et même mot-clé et que des mots séparés par des espaces.
- Ramasse-miettes. Une sorte de "ramasse-miettes" a été activité (il existait, mais sans être activé sur la version publique d'Alyze). Il élimine une expression si elle est contenue dans une autre expression plus longue. Exemple : si une page comporte plusieurs fois l'expression "le seo n'est pas mort", les expressions plus courtes comme "le seo n'est pas", "n'est pas mort" ou "pas mort" ne seront pas affichées. Le ramasse-miettes ne ramasse que les expressions de plusieurs mots. Dans notre exemple, "seo", "mort", etc. seront bien affichés.
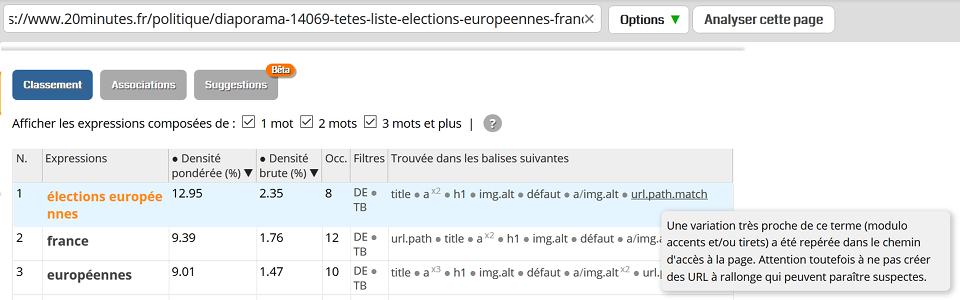
- URL avec accents. Les mots-clés sans accents présents dans l'URL sont détectés (que ce soit dans le path ou l'host). Par exemple si une page contient le terme Wikipédia sur le domaine wikipedia.org, Alyze saura mettre en relation les deux termes malgré la différence d'accent. Si un mot-clé est détecté par cette méthode, vous pouvez le voir dans la colonne indiquant le nom des balises. Vous y trouverez "url.host.match" et/ou "url.path.match" selon le cas (voir les exemples ci-dessous).
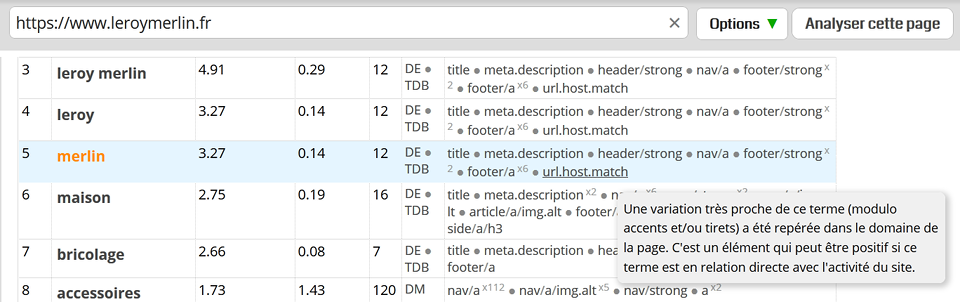
- Host et tirets. Toujours concernant les URL, des mots-clés présents sur la page sont détectés s'ils sont présents aussi dans le nom de domaine, même en l'absence de tiret (c'est là la nouveauté). Par exemple, leroymerlin.fr sera associé à Leroy Merlin.
Après pas mal de tests, ça semble dans l'ensemble meilleur que ce que c'était. Le code est en tout cas beaucoup plus propre ! Ce type de modification expose pourtant à des régressions par-ci par-là. En cas de besoin, vous pouvez me les signaler avec le formulaire de contact.