Contrôlez l'usage de vos contenus par l'IA avec la directive Content-Signal du robots.txt 🤖

Le géant Cloudflare propose d’ajouter une directive au fichier robots.txt pour contrôler ce que les IA peuvent faire de vos contenus. C’est l’une des initiatives les plus prometteuses en la matière, non seulement parce qu’elle est simple et cohérente, mais aussi parce qu’elle est promue par l’une des entreprises les plus puissantes du web après Google.
(Je suis conscient qu’il y a un paradoxe à demander à une IA de faire une vidéo pour expliquer comment se protéger des IA, merci de ne pas m’en faire la réflexion 😅).
L’IA ou le passager clandestin du web
Soyons honnêtes, la révolution des IA génératives repose en bonne partie sur le pillage de contenus. ChatGPT, Perplexity, Gemini et les autres se nourrissent de tout ce qui est accessible sur le web. Le problème, c’est qu’elles ne créditent et ne rémunèrent en rien ceux qui les ont abreuvés sans le vouloir et, la plupart du temps, sans même le savoir.
Il y a une rupture du contrat implicite qui liait les acteurs du web jusqu’à présent : les moteurs de recherche pouvaient explorer les sites qui ne l’interdisaient pas, en échange, les moteurs de recherche renvoyaient des visiteurs vers ces mêmes sites. Une bonne partie du modèle économique du web que nous connaissons repose sur ce postulat.
Aussi géniale qu’elles soient, les IA détruisent cet équilibre. Elles se servent et n’offrent rien en échange aux éditeurs. Les quelques rares citations que les LLM veulent bien faire lors de leurs réponses sont sans commune mesure avec le savoir acquis par les IA sur le web. Les IA sont des boîtes noires qui ne dévoilent généralement rien de leurs sources.
Les solutions existantes
Depuis l’émergence de ChatGPT, les éditeurs cherchent des moyens de se prémunir. Les gros ont souvent les moyens de signer directement des accords avec les grands noms de l’IA. Tout le monde y trouve son compte, car les IA ont un besoin vital de données pour prospérer. Pour les plus petits éditeurs, c’est-à-dire 80% du web, c’est plus compliqué.
Deux pistes ont été explorées par les éditeurs :
- Bloquer, avec ce bon vieux fichier robots.txt, les robots des IA.
- Fournir avec le protocole TDMRep une politique en matière de data mining.
Alors que TDMRep propose une solution complète, son adoption et, surtout, son respect par les IA semblent aléatoire. L’utilisation du fichier robots.txt est plus simple et mieux comprise par les IA (du moins, celles qui le respectent).
Il y a pourtant plusieurs soucis à bloquer entièrement l’accès aux robots IA. D’abord, il faut connaître leur user-agent. Ça évolue beaucoup, il y en a des nouveaux sans arrêt, certains peuvent aussi mélanger les bots destinés à leurs moteurs de recherche et leurs bots IA (coucou Google). Il serait dommage de se déréférencer de Google pour se préserver de Gemini !
Ensuite, il y a une zone floue à propos des recherches par l’IA, comme les AI Overviews de Google ou les recherches effectuées en temps réel par Grok ou ChatGPT lorsque l’utilisateur a besoin de données précises et actualisées. Cet usage est une source potentielle de citations par les IA et de trafic qualifié. Il peut être légitime de l’autoriser tout en bloquant l’entraînement d’un modèle sur son site. Les solutions existantes ne permettent pas de préciser avec finesse ce que l’on veut bloquer.
La solution proposée par Cloudflare
C’est là qu’intervient Cloudflare et son idée d’ajouter une simple directive Content-Signal au robots.txt pour définir des préférences. À la différence d’initiatives comme LLMs.txt, je pense bien que cette idée peut prendre.
Tout d’abord, Cloudflare n’est pas n’importe qui. Il contrôle une bonne partie du trafic du web en proposant la solution de CDN la plus populaire au monde avec près de 80% de part de marché. L’entreprise fait preuve d’une innovation constante et bénéficie d’une bonne réputation auprès des éditeurs. C’est aujourd’hui un maillon essentiel de l’infrastructure du web. Cloudflare se donne les moyens de populariser son idée : création d’un site web dédié, article pédagogique. Surtout, Cloudflare propose d’automatiser l’insertion de cette directive pour les domaines qu’il gère. C’est déjà le cas pour 3,8 millions de sites ! S’il va sans dire que vous pouvez utiliser cette directive sans utiliser Cloudflare, la force de frappe du géant de San Francisco devrait beaucoup aider à son adoption.
Ensuite, le système est simple et efficace. Il nécessite simplement d’ajouter des commentaires en tête du fichier robots.txt (on y reviendra) puis une simple directive qui s’intègre comme ceci dans votre robots.txt :
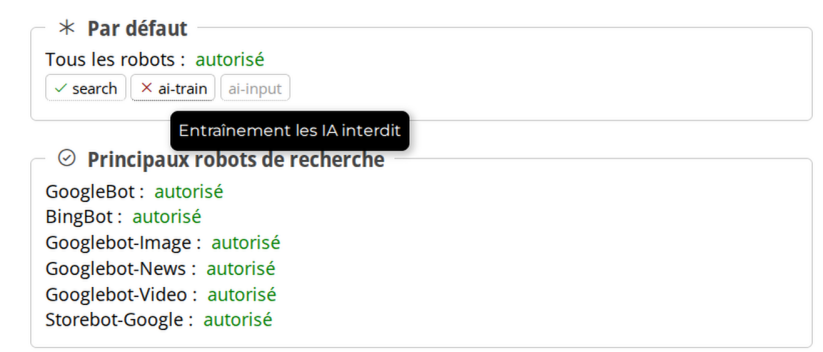
User-Agent: *
Content-Signal: ai-train=yes, search=yes, ai-input=yes
Allow: /Vous avez déjà repéré la nouvelle directive, c’est celle qui commence par Content-Signal. Les autres lignes restent exactement les mêmes et ont exactement la même signification. Dans l’exemple ci-dessus, tous les robots (*) sont autorisés à explorer le site (« Allow : / »). La directive Content-Signal s’applique également à tous les robots, mais rien n’empêche de la spécifier pour un robot particulier, par exemple Googlebot :
User-Agent: googlebot
Content-Signal: ai-train=no, search=yes, ai-input=yes
Allow: /Il est également possible de limiter l’application des règles à une partie du site. Pour cela, il faut préciser le chemin où les règles s’appliqueront. Ce chemin doit être inséré juste avant les règles du Content-Signal. Dans l’exemple ci-dessous, les préférences en matière de Content-Signal seront valables pour tout ce qui se trouve dans le répertoire /blog/ sur le site :
User-Agent: *
Content-Signal: /blog/ ai-train=no, search=yes, ai-input=yes
Allow: /blog/Venons-en maintenant au contenu de ce Content-Signal. Il indique les préférences pour trois types d’opération séparés par des virgules :
- ai-train définit une préférence concernant l’entraînement des modèles d’IA.
- ai-train=yes indique que l’entraînement est autorisé sur les contenus du site.
- ai-train=no indique au contraire qu’il est interdit d’utiliser les contenus concernés pour entraîner une IA.
- ai-input définit une préférence concernant l’utilisation par les IA de vos contenus pour enrichir des réponses (AI Overviews, recherche en temps réel, etc.).
- ai-input=yes autorise l’usage des contenus pour enrichir les réponses des IA,
- ai-input=no indique qu’il est interdit d’utiliser les contenus pour enrichir les réponses des IA.
- search définit une préférence concernant la construction d’un index de recherche comme celui de Google ou Bing sans utilisation de l’IA (AI Overviews et équivalent). En clair, il s’agit de la recherche traditionnelle.
- search=yes permet d’utiliser les contenus pour construire un index de recherche,
- search=no interdit cet usage.
Une solution d’avenir ?
Est-ce que les IA vont respecter cette directive ? À vrai dire, ça dépendra largement de son adoption par les éditeurs ! C’est l’une des raisons qui me pousse à en parler ici à ma petite échelle.
Malgré tout, juridiquement, le mécanisme a de bons arguments pour lui. Il s’appuie, dans l’Union européenne, sur la Directive du 17 avril 2019 (2019/790) portant sur le droit d’auteur et les droits voisins. Exactement comme je vous l’expliquais dans mon article sur le protocole TDMRep. La force juridique des préférences exprimées me paraît d’ailleurs assez forte. En effet, Cloudflare précise bien qu’il faut pour utiliser ce protocole inclure des commentaires dans le fichier robots.txt. Cloudflare propose ce modèle (toutes les lignes commençant par # sont des commentaires dans un fichier robots.txt) :
# As a condition of accessing this website, you agree to abide by
# the following content signals:
# (a) If a content-signal = yes, you may collect content for the
# corresponding use.
# (b) If a content-signal = no, you may not collect content for
# the corresponding use.
# (c) If the website operator does not include a content signal
# for a corresponding use, the website operator neither grants nor
# restricts permission via content signal with respect to the
# corresponding use.
# The content signals and their meanings are:
# search: building a search index and providing search results
# (e.g., returning hyperlinks and short excerpts from your
# website's contents). Search does not include providing
# AI-generated search summaries.
# ai-input: inputting content into one or more AI models (e.g.,
# retrieval augmented generation, grounding, or other real-time
# taking of content for generative AI search answers).
# ai-train: training or fine-tuning AI models.
# ANY RESTRICTIONS EXPRESSED VIA CONTENT SIGNALS ARE EXPRESS
# RESERVATIONS OF RIGHTS UNDER ARTICLE 4 OF THE EUROPEAN UNION
# DIRECTIVE 2019/790 ON COPYRIGHT AND RELATED RIGHTS IN THE
# DIGITAL SINGLE MARKET.
User-Agent: *
Content-Signal: ai-train=yes, search=yes, ai-input=yes
Allow: /Comme vous le voyez, l’acceptation de ce mécanisme est érigée en condition pour l’accès au site web. C’est logiquement imparable : pour accéder à ce site, il faut accepter d’utiliser le mécanisme Content-Signal. Comme l’usage impose de lire le fichier robots.txt avant d’explorer un site avec un robot, cette condition est forcément rencontrée et lue.
Il a cependant une petite faille à mon avis. Comme son nom l’indique, le fichier robots.txt est destiné à des… robots. Les commentaires ne sont pas censés être lus par des humains. Toutefois, on pourrait aussi faire l’analogie avec les licences libres dont l’efficacité juridique est reconnue et repose sur un mécanisme voisin. En résumé : vous n’avez pas d’autres droits que cette licence pour utiliser ce logiciel, vous en acceptez donc les termes. C’est très proche de ce qui se trouve dans ce fichier robots.txt : « si vous lisez ça, vous acceptez nos conditions sinon vous êtes libres de ne pas explorer ce site ».
Pour renforcer la force du message, rien n’empêche d’utiliser en parallèle le protocole TDMRep qui peut d’ailleurs venir en complément, en particulier pour indiquer les moyens d’obtenir une licence.
Vérifiez votre implantation avec Alyze
J’ai décidé d’inclure l’analyse de cette directive dans le testeur de robots.txt et sur l’analyseur SEO. En premier lieu parce que je trouve ce mécanisme utile. Je pense important de le faire connaître et de le populariser.
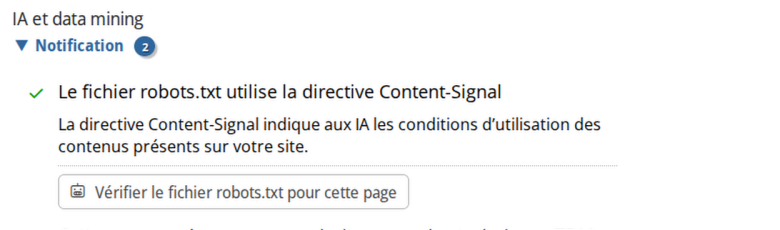
Je ne peux encore vous garantir que ces préférences seront respectées à 100% par les IA. Mais je peux vous garantir (à 100% cette fois !) qui si vous ne faites rien, les AI continueront à se nourrir de vos contenus sans aucune contrepartie.